
Using a Neural Network to Solve a Polynomial
Design and execution of an unconventional polynomial solver.
In the fall of 2018 I met a very talented machine learning practitioner who showed me how to solve an integro-differential equation using a neural network. He had considerable experience designing and implementing neural networks as well as knowledge of the theory. This post is a baby step in my pursuit of his knowledge.
Before jumping in to more complicated equations he started with a simple polynomial.
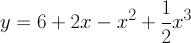
According to the universal approximation theorem, all we need to do to find y is to pass x through a feed-forward network with a single hidden layer. Here is one such network.
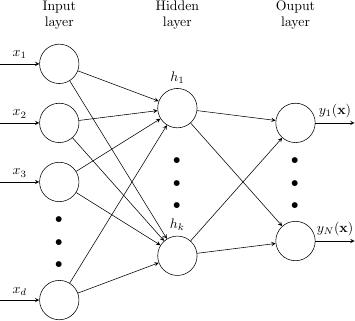
Because polynomials are functions there is one y value that corresponds to each x value, so we will use the same number of nodes in the input layer and output layer, meaning d and N will be equal.
Learning with data versus learning an equation
In traditional learning applications like image classification we would partition our image set into training images and test images, select a loss function, and then pass the training images through the network. Learning an equation, by contrast, does not employ a data set. To solve our polynomial we create a single vector of one hundred coordinates on the x-axis uniformly spaced between -3 and 3 which we pass through the network over and over again until we achieve the convergence criterion.
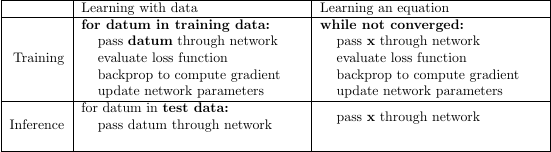
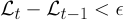
Our loss function contains the polynomial that we are approximating. In traditional learning applications a single loss function may be applied to multiple problem domains. Here, because the loss function contains the equation, a different loss function would be necessary for learning a different equation.
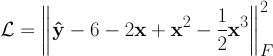
The optimizer is responsible for updating the network parameters such that the next pass results in a smaller loss. We employ the Adam optimizer, which is a popular variation on stochastic gradient descent.
Learning the polynomial
We use PyTorch to implement our model.
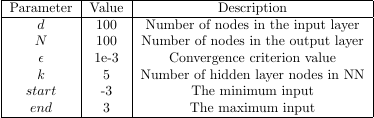
We provide the extent of the domain when we run the model: "poly.py -3 3". On my Ryzen 5 2400g it takes just 3.5 seconds to converge.
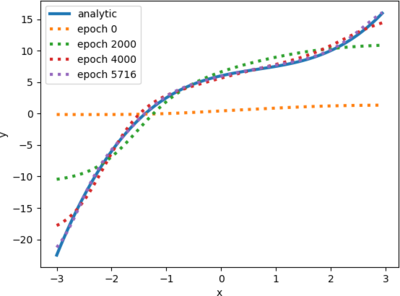
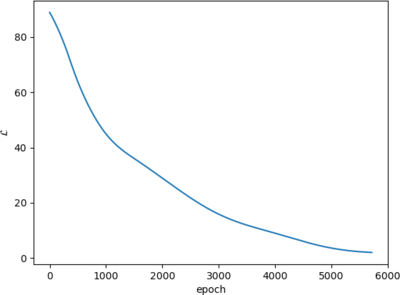
Where to go from here
We could solve more interesting equations, like differential equations, integro-differential equations, and multivariate equations. We could also try to understand our network better with a parameter study where we try changing network qualities. Examples include
- learning rate
- optimizer
- number of hidden layers
- number of nodes in the hidden layer(s)
- number of nodes in the input/output layers
- network connectivity
We could try interpolating and extrapolating. We could also look at the performance profile of the network. We could try using a GPU.
Send me your suggestions. My email is in my resume.